Most of developers of web-sites, web-services and mobile applications at some point come to work with the client-server architecture, namely to develop or integrate a web API. To avoid inventing something new each time, it is important to draw out a relatively universal approach to web API design, based on the development experience of similar systems. We would like to introduce you the first, introductory part of the series of articles about this question by our web-developer Vladimir.
First approach: participants
Once, being in the process of creating yet another web-service, I decided to gather all my knowledge and reflections on the subject of design of web API supporting the needs of client applications and arrange them as an article of a series of them. My experience naturally doesn’t claim to be the absolute, and any constructive comments and additions are more than welcome.
The reading came out to be more philosophical than technical, but enthusiasts of the technicalities will also find here something to think about. I doubt that in this article I will declare something revolutionary new, something that you never read, heard or thought about. I’m just going to try to organize it all, in my own head in the first place, which is already worth much. However, I will be glad if my reflections could prove themselves useful in your practice. So, here it goes.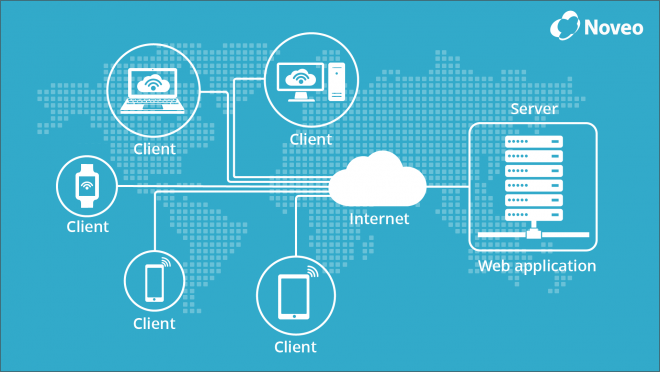
Client and Server
By server in this case we mean an abstract engine in the network, able to receive an HTTP-request, process it and return a correct answer. In the context of this article its physical essence and internal architecture absolutely don’t matter, be it a student’s notebook or an enormous cluster of commercial servers, distributed around the world. It is as well of no importance, what there is under the hood, if it is Apache or Nginx who welcomes the request at the entry, what mysterious creature — PHP, Python or Ruby — performs its handling and forms the answer, what data warehouse - PostgreSQL, MySQL or MongoDB — is used… The important thing is that the server conforms to the main regulation — to receive, perceive and forgive respond.
As client can also serve pretty much everything, that is capable of forming and sending an HTTP-request. Up to a certain point in this article we are also not particularly interested in goals that the client sets itself while sending the request, as well as in actions it will apply to the answer. A client can be a JavaScript scenario working in browser, a mobile application, an evil (or not so much) daemon launched on the server, or a fridge that got too smart (nowadays they exist).
We will mostly discuss the way of communication between the two participants given above, the way ensuring that they understand each other and neither of them has any questions pending.
REST PHILOSOPHY
REST (Representational state transfer) was initially designed as simple and explicit interface for data management, involving only some basic operations with actual network repository (server): data retrieval (GET), saving (POST), changing (PUT/PATCH) and removal (DELETE). This list was of course always followed by such options as error handling in request (whether the request was formed correctly), data access control (in case you’re not supposed to know it) and incoming data validation (if you wrote some nonsense), basically by all possible verifications that the server effectuates before fulfilling the client’s wish.
Apart from that REST has a number of architectural principles, whose description can be found in any other article concerning REST. Let’s briefly enumerate them so that they are at hand and we don’t have to go elsewhere to find them:
Server’s independence from the client — servers and clients can be replaced by the other ones in a split of a second independently from each other, as the interface between them doesn’t change. The server doesn’t store the client’s states.
Uniqueness of the resources addresses — every data unit (of any nesting level) has its own unique URL, which actually represents in the whole a unique identifier of the resource.
Example: GET /api/v1/users/25/name
Independence of the data storage format from their transmission format — server can support several different formats for transmission of the same data ((JSON, XML etc), but it stores the data in its own internal format, independently of the supported ones.
Presence of all required metadata in the answer — along with the data themselves the server should return the details of the request processing, such as error messages, different resource properties needed for the further work with it, like total records in the collection for the correct display of paginal navigation. Later we will also run through the different types of resources.
WHAT IS MISSING

Classical REST implies the client working with the server as a flat data repository, and nothing is said about data connexion and interdependencies. All this by default falls on the shoulders of the client application. However, the actual domains for which the data management systems are developed, be it social services or internet-marketing systems, involve a complex correlation between entities stored in the database. Supporting these connections, that is data consistency, falls under the responsibility of the server side, while the client presents only an interface for accessing these data. So what do we miss in REST?
Function calls
In order not to change data and connexions between them manually, we just call a function of the resource and “feed” it with the required data as an argument. This operation doesn’t match the REST standards, there is no dedicated verb for it, which makes us, developers, to get ourselves out each in his own way.
The simplest example is a user authorization. We call the login function, hand it over an object containing credentials as an argument, and receive an access key in response. What happens with the data on the server side, is of no concern to us.
Another variant is creating and breaking connections between the data. For example, adding a user to a group. We call the addUser function of the group entity, transmit the user object as a parameter and receive the result.
There are also operations absolutely not connected directly to the saving data themselves, for example, sending notifications, confirmation or rejection of some operations (report period termination etc).
In one of the next articles I will try to classify these operations and offer possible variants of requests and answers, basing on my own experience of working with them.
Multiple operations
It’s not a rare situation, and developers of clients will understand me perfectly, when it is more convenient for a client application to create/modify/delete several similar objects at once with one request, and on each object its own verdict of the server side is possible. There are at least several variants: whether all modifications are effectuated, or they are effectuated only partially (for some of the objects), or an error occurred. So there also are several strategies: apply modifications only in case of success for all, or apply partially, or roll back in case of any error, which already approaches a proper transactions mechanism.
For a web API aiming for ideal I would also like to arrange similar operations in a system somehow. I’ll try to do it in one of the following articles.
Statistical requests, aggregators, data formating
It is a frequent case, that on the basis of data stored on the server we need to obtain a statistical summary or data in particular format: for example, to build a graphic on the client side. Basically these are data, generated on request, more or less in passing, and available for reading only, so it makes sense to class them as a separate category. One of the distinguishing features of statistical data is, in my opinion, the fact that they don’t have a unique ID. I’m sure that it’s by far not all that can be met while developing real applications and will be glad if you could add/correct something.
I’m sure that it’s by far not all that can be met while developing real applications and will be glad if you could add/correct something.
DATA TYPES
Objects
The key data type in client-server communication is object. As a matter of fact, an object is a set of properties and corresponding values. We can send an object in a request to the server and receive an object as a request result. At the same time an object is not necessarily a real entity stored in the database, at least the way it was sent or received. For example, credentials for authorization are transmitted as an object, but don’t represent an independent entity. Even objects stored in the database tend to become overgrown with additional properties of intrasystem character, like creation and editing date, different system marks and flags. Objects’ properties can be separate scalar values as well as contain linked objects and object collections, which are not a part of the object itself. Some of the object properties can be editable, some of them — system-internal and available for reading only, and some can even be of statistical nature and be calculated on the fly (e.g., likes number). Some of the object properties can be hidden depending on the user’s rights.
Object collections
Speaking of collections, we mean the sort of the server resource allowing to work with a list of similar objects, in other words — add, delete, change objects and retrieve a sample of them. Beyond that, a collection can theoretically have its own properties (like maximal number of elements for a page) and functions (here I am confused, but it did happen).
Scalar values
My memory barely registers meeting scalar values as a separate entity in their pure form. Usually they were present as properties of objects or collections, and as such they can be available for reading as well as for writing. For example, a user name can be received and modified individually GET /users/1/name. In praxis this possibility is rarely useful, but it is good to have it at hand if needed. It especially concerns collection properties, for example entries number (with or without filtration): GET /news/count.