Noveo Senior developer Kirill concludes his story about working with eBPF. In this new part — important nuances that remained behind the scenes, and the results of a large‑scale task.
In the previous part, I analyzed the problems I encountered while developing eBPF programs, and also explained which features of eBPF should be taken into account when writing code. At the time of developing the solution, LLMs knew very little about eBPF code and its verification, but today even ChatGPT does a decent job of explaining verification errors and giving relevant advice on fixing code, so I recommend involving it in your work.
And in this final part, we will cover the remaining points:
- Is it worth sending a copy of the packet to the same interface?
- How to improve program performance?
- What obstacles exist for developing a proprietary solution?
- Conclusions from working with eBPF
Working with Packet Redirection
In the first part, I mentioned using the bpf_clone_redirect function to redirect a copy of the packet to another interface. In the first version, I worked with the original packet — expanded it, cloned it, sent it to the destination, and then restored it. But the need for fragmentation significantly complicated this process, and a new architectural solution was found.
In short, the idea was this: we take the packet, send its copy to the same interface where we received it, let the original go peacefully on its way further through the Linux network stack, and then with the copy we do whatever we want — fragment it, tack on headers, send it to destinations. This also eliminates the need to restore the original packet.
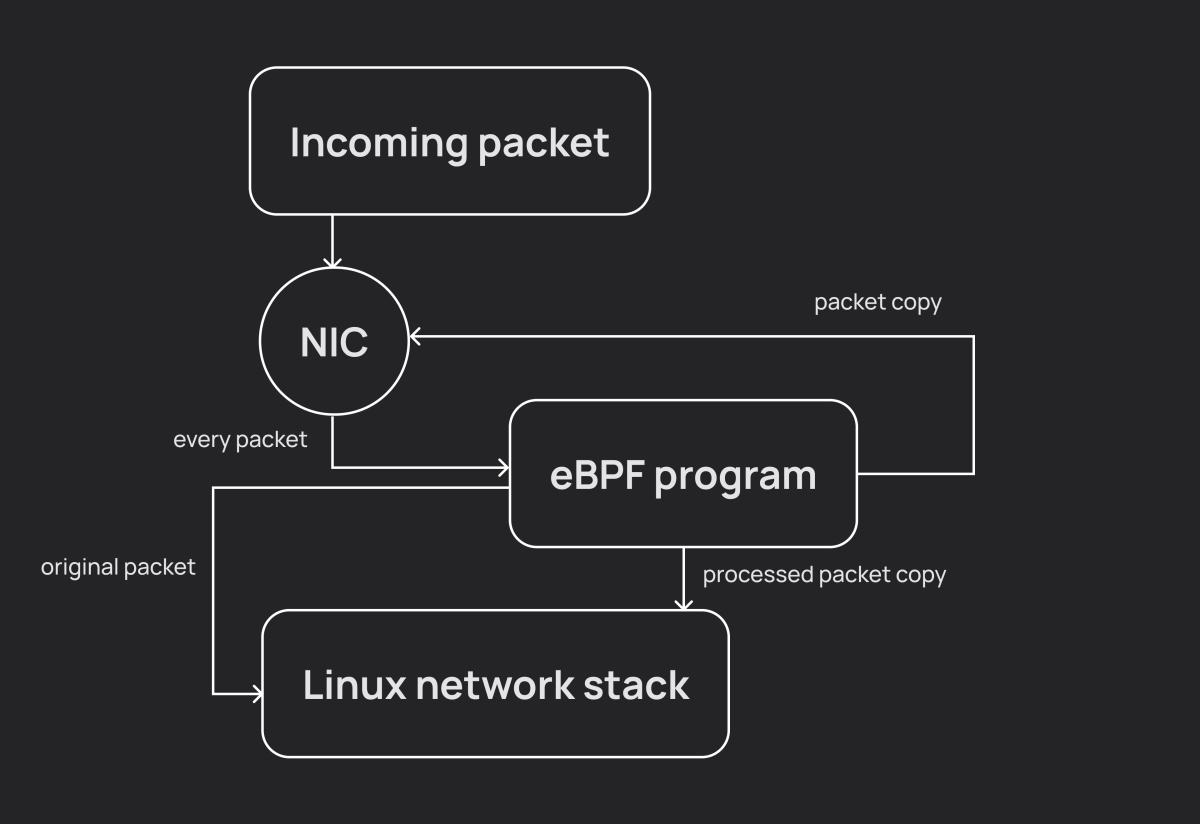
Sounds good, and it even works as intended, but with one nuance: ingress packets are visible in the system, including in traffic sniffers (I made this unpleasant discovery while validating fragmentation in Wireshark). Moreover, for egress packets there is no such problem because in TC programs we place the packet into the output queue after all OS handlers. This behavior is unacceptable for us, because the eBPF program's impact on traffic is visible to the naked eye (well, okay, almost the naked eye).
Dev Humor Corner 1

I saw two solutions to the problem: radically change the existing architecture, or hide this duplicate traffic somewhere where it wouldn't stand out. I chose the second option, and for ingress traffic I started redirecting packets not to my own interface, but to loopback (dummy interfaces could also be used, but then performance would need to be tested for each option separately), where an eBPF program was also attached. At that moment a question arose — how to figure out on the loopback which interface the copy came from? Fortunately, the struct __sk_buff has readable/writable fields u32 mark and u32 cb[5], which can be used to pass small amounts of information — this was ideal for passing flags and the network interface index.
Thus, egress traffic was processed on the main interface, and ingress traffic on the auxiliary one. This scheme worked without problems on bare Linux, on virtual machines, on pods in an Amazon EKS cluster, but unexpectedly ran into issues in an Azure/AKS environment when the cluster was configured without Cilium. The solution deployed without errors, the eBPF programs loaded, but as soon as traffic was sent through the interface, the entire node crashed due to a SIGBUS in the kernel. Investigating the problem showed that there is most likely a bug in the kernel, and we hit it because we are using multiple packet redirection in an eBPF program. In other words, the architecture described at the beginning turned out to be completely unsuitable for this particular case. Therefore, when developing your eBPF solution, it's worth keeping such scenarios in mind as well.
Trying to Improve Performance
First, it's worth understanding how our program will affect the system. Obviously, additional actions when processing each packet will lead to a decrease in the overall throughput of the network interface. In previous articles, I didn't go into the details of the original task I was faced with, because that information isn't public, but please take my word for it — the packet processing logic is quite complex, so every packet, even if it ultimately doesn't need to be sent anywhere, goes through a large system of checks.
Our tests after all optimizations and code improvements showed the following results.
When the system is loaded with traffic that should not be tunneled:
- at channel utilization up to 75%, losses are minimal — <0.01%,
- at channel utilization of 75-85%, losses are around 3-4%,
- at channel utilization of 85-99%, losses are around 7-8%.
When the system is loaded with traffic that is tunneled:
- at channel utilization up to 65%, losses are minimal — <0.01%, all traffic is tunneled,
- at channel utilization of 65-85%, losses are around 5%, with 5-8% of this traffic not being sent to the tunnel,
- at channel utilization of 85-99%, losses are around 15%, with up to 20% of this traffic not being sent to the tunnel.
The result was deemed satisfactory, but certainly not ideal. The first version lost even more packets, but we managed to achieve some improvements.
First, I eliminated unnecessary packet cloning operations. Memory allocation is always a slow operation, so the fewer times we do it, the better. Places where I managed to optimize:
- one packet can be sent to several tunnels of different types, so the additional headers will have different sizes. Therefore, we first calculate and allocate the maximum packet size, and then gradually shrink it (remember, shrinking the packet does not allocate new memory);
- the last packet can be sent not with
bpf_clone_redirect, but withbpf_redirect. In this case, no additional copying occurs either.
Second, I did something quite obvious — refactored the code, reducing the number of branches and loop iterations.
I wouldn't claim that I wrote the best possible version of the code, but neither I nor my reviewers could find any obvious places where additional optimizations could be made to improve performance. Remember this conclusion — I'll return to it at the end of the article. For now, there are a couple more interesting points I'd like to touch on.
How Not to Violate the GPL License
When it comes to commercial development of Linux-based solutions, you should always keep the issue of code licensing in mind. eBPF program development is no exception — if you use any GPL-licensed functions without including information about a compatible license in your program, the verifier will not let such code through, and none of the tricks I described in the previous part will help.
Dev Humor Corner 2

Fortunately, there aren't many such functions, and those that exist don't carry critically important functionality (or at least I haven't encountered any). In this project, I only had to give up two functions:
bpf_printk— printing formatted strings to the log. A convenient function out of the box, but not too hard to replace. Add a map, run a daemon in userspace that listens to that map and dumps content as needed. I wanted to cheat the system and use at leastbpf_snprintfto avoid dealing with formatting, but it, of course, also turned out to be under GPL. Had to do formatting manually as well.bpf_check_mtu— a handy function that checks whether a packet will fit into the specified interface. Without it, I had to check everything manually, but this didn't cause any particular difficulties either.
Therefore, I recommend including GPL for debugging, because bpf_printk is very convenient in that case, but overall, there's no need to expect major problems from the absence of GPL.
Running in a Cluster
There isn't much for me to say on this point, because this is more DevOps territory. Actually, together with one of them, we deployed our solution for the first time. However, I think it's worth mentioning a few things that I personally only learned while working on the solution:
- carefully investigate whether other eBPF programs are already running on the target interfaces, and if so, study how you can integrate your program into the existing chain (you'll need to play around with priorities);
- your container will run on a pod, and you need to run it in privileged mode, since any work with eBPF requires this;
- the eBPF program runs in the kernel, so even though you're working with it in a pod, it will affect the kernel of the entire node.
Conclusions
The original task has been completed in full, functionally meeting all requirements, which proves that the eBPF technology has enormous potential, including for solving fairly complex problems directly in kernel space, even if sometimes through not‑so‑obvious tricks.
But, as I wrote above, the current version of the solution has issues that could become reasons to abandon eBPF (of course, I mean exclusively packet processing, as I have no practical experience with other areas), namely:
- significant impact on the original traffic in the system;
- difficulties with extending the program, with adding new functionality (new requirements can lead to an unpredictably long process of transforming the program into a form accepted by the verifier, up to restructuring its entire architecture);
- critical infrastructure bugs. The eBPF technology is actively developing, which on one hand is wonderful, but on the other hand, we're dealing with a technology that hasn't been battle‑tested over years of use. The probability of getting a system kernel crash that is largely independent of the developer is hardly something anyone wants.
Thus, in the next version, the role of eBPF will be significantly reduced. We plan to leave primary packet processing in the kernel, but handle complex operations like fragmentation in userspace. How much we'll manage to reduce losses of original traffic and whether we'll be able to tunnel packets at the same level — time will tell, but solving problems #2 and #3 will definitely be achievable.
In any case, it was worth doing all these complicated things only to later abandon them, because even if we never reach perfection, we can still iteratively move closer to it. I hope you found it useful (or at least interesting) to spend a little time with eBPF and my experience.